
Feldname mit doppeltem Feldnamen
Hä?
Die nordfriesisch höfliche Nachfrage ist berechtigt. Wie kann ein Feldname einen doppelten Feldnamen besitzen? Aber der Reihe nach. Erst das Problem, dann die Idee und zum Schluss die Lösung.
MOVE-CORRESPONDING
Der MOVE-CORRESPONDING-Befehl ist sehr bequem. Man kann einfach alle Felder einer Struktur in die gleichnamigen Felder einer anderen Struktur kopieren. Wird ein neues Feld in die Strukturen eingefügt, wird es automatisch berücksichtigt.
<offtopic>Eigentlich müsste der Befehl dann ja COPY-CORRESPONDING heißen, denn der Feldinhalt wird ja nicht verschoben, sondern kopiert…</offtopic>.
Der Befehl birgt aber auch Tücken, denn die Feldnamen müssen immer gleich sein. Häufig hat man jedoch den Fall, dass Feldnamen – trotz gleicher Funktion und gleichem Datenelement – in verschiedenen Strukturen anders heißen. Zum Beispiel könnte das Feld in der Quellstruktur LIFNR heißen, in der Zielstruktur heißt es jedoch LIEFERANT.
Ein nachträgliches MOVE ist in diesem Fall erforderlich:
MOVE quell_struktur-lifnr TO ziel_struktrur-lieferant.
Das ist nicht weiter schlimm. Wenn man jedoch eine dynamische Struktur als Quellstruktur hat, dann muss man umständlich mittels ASSIGN COMPONENT den Quellwert lesen und dann zuweisen. Das ist umständlich und gegebenenfalls auch zeitkritisch.
ASSIGN COMPONENT 'LIFNR' OF STRUCTURE dynamische_quell_struktur TO FIELD-SYMBOLS(<lifnr>). IF sy-subrc = 0. ziel_struktur-lieferant = <lifnr>. ENDIF.
Sofern es sich um kundeneigene Tabellen handelt, kann man den folgenden Trick anwenden und quasi einen ALIAS vergeben:
ALIAS-Feldname
Stichwort: Benanntes Include. Wir machen uns den Umstand zu Nutze, dass man ein Include in eine Tabelle einbinden kann und dieses Include benennen kann. Das ist eigentlich für inkludierte Strukturen gedacht, um zum Beispiel die komplette Tabelle MARA per Include einbinden zu können und diese auch MARA benennen zu können. Die komplette Struktur MARA steht dann in der inkludierten Struktur zur Verfügung:
SELECT * FROM MARA INTO my_struc-mara WHERE...
Wir verwenden diese Gruppe nun nicht für eine inkludierte Struktur, sondern nur für ein inkludiertes Feld. Die Technik ist die gleiche.
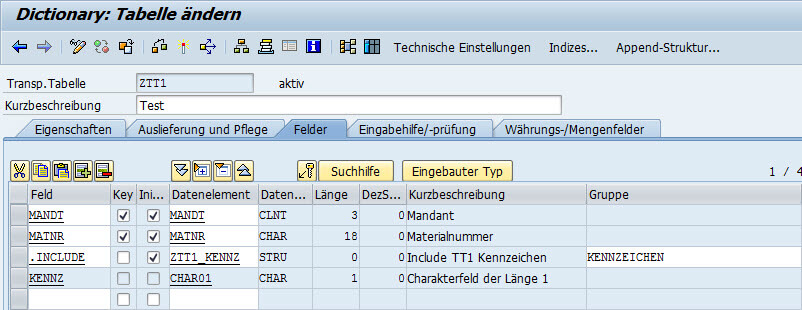
Die Tabelle bestand vorher aus den Feldern
- MANDT
- MATNR
- KENNZ
Ich möchte diese Tabelle nun so abändern, dass das Feld KENNZ auch unter dem Namen KENNZEICHEN ansprechbar ist. Dafür lege ich einen Include an, der nur das eine Feld KENNZ enthält. Dieses Include wird in die Tabelle eingebunden:
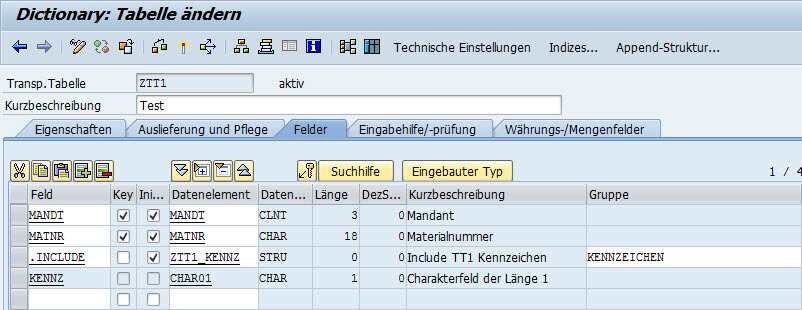
Die Struktur der Tabelle ist hinterher genau so, wie vorher:
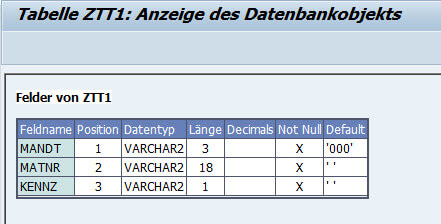
Die richtige Ansprache
Den Vorteil, den ich jetzt habe: ich kann das Feld mit dem richtigen Namen KENNZ und mit dem Alias KENNZEICHEN, dem Gruppennamen des Includes ansprechen:
DATA lt_tt1 TYPE STANDARD TABLE OF ztt1. DATA ls_tt1 TYPE ztt1. SELECT * FROM ztt1 INTO TABLE lt_tt1. LOOP AT lt_tt1 INTO ls_tt1. IF ls_tt1-kennz = 'X'. ls_tt1-kennzeichen = 'F'. ENDIF. WRITE: / ls_tt1-matnr, ls_tt1-kennz. ENDLOOP.

- IMG-Struktur anzeigen - 11. März 2024
- ALV-Grid und Dropdown - 8. März 2024
- Finden ─ nicht suchen - 28. Februar 2024

Ich bin mir jetzt mal nicht so ganz sicher, ob das wirklich weniger kompliziert ist 😉 Zumal ich ja für jedes einzelne Feld jeweils einen Include machen muss.
Gibt es zu dem Aspekt ‘Geschwindigkeit’ irgendwelche Vergleichswerte?
Es kommt halt drauf an…Der Königsweg ist das sicherlich nicht. Aber immerhin eine Alternative. 😉
Performancemessungen habe ich nicht gemacht.
Danke für diesen interessanten Artikel!
Allerdings finde ich das Verb “modifizieren” in Zusammenhang mit einer kundeneigenen Tabelle im SAP-Umfeld etwas unangemessen 😉
Ich glaube, du bist schon zu sehr SAP-geschädigt! 😉
Habe “modifizieren” zu “abgeändert” abgeändert.
Das könnte in der Tat etwas verwirrend sein.
Danke!