
Kaskadiertes Lesen von Einträgen

Viele Prozesse und Funktionen werden im SAP über Customizingtabellen gesteuert. Bei Tabellen mit mehreren Schlüsselfeldern wird häufig eine stufenweise Verarbeitung zugelassen. Das bedeutet, dass nicht der komplette Schlüssel definiert werden muss, sondern es reichen Teile des Schlüssels. In der Regel wird der Lesezugriff so lange mit weniger qualifiziertem Zugriff erfolgen, bis ein Eintrag gefunden wurde.
Nehmen wir an, in einem Prozess soll anhand von Werk. Lagerort und Material gesteuert werden, ob bei der Auftragserfassung für ein Material eine bestimmte Prüfung erfolgen soll. Die Tabelle wird dann folgendermaßen aussehen:
| Feldname | Beschreibung |
| WERKS | Werk |
| LGORT | Lagerort |
| MATNR | Material |
[notice type=’info’]Der Mandant gehört (fast) immer in die Tabelle. Da er hier jedoch keine Bedeutung hat, betrachte ich ihn nicht.[/notice]
Tabellenpflege
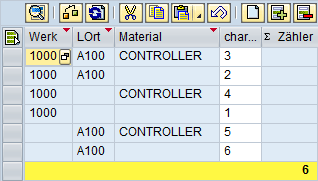
Die Einträge in der Tabelle sollen bewirken, dass für verschiedene Kombinationen eine Prüfung ausgeführt wird. Dabei muss nicht der vollständige Schlüssel – also Werk und Lagerort und Materialnummer – eingegeben werden, sondern es reicht, wenn auch zum Beispiel nur die Materialnummer eingetragen wird. Die Spalte Index dient lediglich der Orientierung, um in der weiteren Beschreibung eindeutig sagen zu können, welcher Eintrag gemeint ist.
| Index | Werk | Lagerort | Materialnummer | Prüfung ja / nein | Beschreibung |
| 1 | 1000 | A100 | CONTROLLER | nein | Gebrauchte Controller aus Lager A100 nicht prüfen |
| 2 | 1000 | A100 | ja | Gebrauchtes Material aus Lager A100 immer prüfen | |
| 3 | 1000 | nein | Generell braucht Material aus Werk “Süd” nicht geprüft werden | ||
| 4 | TELEFON | ja | Telefone immer prüfen! | ||
| 5 | 2000 | TELEFON | nein | außer Sie kommen aus Werk “Nord” | |
| 6 | RET1 | ja | Materialien aus dem Retourenlager immer prüfen | ||
| 7 | RET1 | SOFTWARE | nein | Ausnahme: Software aus Retourenlager nicht prüfen |
Einträge der Tabelle ZPRUEF1
Kaskadierter Zugriff
Bei einem kaskadierten Zugriff auf die Tabelle muss genau definiert werden, in welche Reihenfolge und mit welchen Feldern der Zugriff erfolgen soll. In der Regel ist der vollqualifizierte Zugriff immer der erste:
SELECT SINGLE pruefung FROM zpruef1 INTO TABLE lt_zpruef1 WHERE werks = i_werks AND lgort = i_lgort AND matnr = i_matnr.
Der nächste Zugriff wäre dann ein Zugriff ohne die Materialnummer:
SELECT SINGLE pruefung FROM zpruef1 INTO TABLE lt_zpruef1 WHERE werks = i_werks AND lgort = i_lgort AND matnr = space.
Wurde dann immer noch kein Eintrag gefunden, so wird ausschließlich mit WERKS gelesen:
SELECT SINGLE pruefung FROM zpruef1 INTO TABLE lt_zpruef1 WHERE werks = i_werks AND lgort = space AND matnr = space.
Das Programm enthält nun bereits drei SELECT-Anweisungen. Und wir haben noch gar nicht die Zugriffe auf die anderen Tabelleneinträge (4-7) codiert. Bei diesen Tabelleneinträgen müssen wir uns entscheiden, in welcher Reihenfolge diese gelesen werden sollen.
Wenn wir hier alle Kombinationen betrachten, dann haben wir zusätzlich zu den bisherigen drei Zugriffen noch die folgenden vier (auf nicht genannte Felder wird mit SPACE zugegriffen):
- WERKS – MATNR
- LGORT – MATNR
- LGORT
- MATNR
Der Vorteil bei diesem Verfahren ist, dass jede benötigte Kombination gezielt programmiert werden kann.
Nachteil ist die große Menge an verschiedenen Zugriffen, die programmiert werden müssen.
Alternative zum kaskadierten Zugriff
Das Lesen der Tabelle mit ODER-Bedingung ist eine andere Möglichkeit, den gewünschten Eintrag zu lesen.
Hierfür lesen wir alle Einträge, bei denen mindestens einer der Felder den gewünschten Werten entspricht:
SELECT * FROM zpruef1 INTO TABLE lt_pruef1 WHERE ( werks = i_werks OR werks = space ) AND ( lgort = i_lgort OR lgort = space ) AND ( matnr = i_matnr OR matnr = space ).
Um den am meisten qualifizierten Tabelleneintrag zu erhalten, sortieren wir dies Tabelle absteigend. Das bewirkt, dass die Einträge, bei denen die Felder mit Werten gefüllt sind, oben stehen.
SORT lt_pruef1 DESCENDING.
Nun müssen wir nur den obersten Eintrag lesen und haben den passenden gefunden:
READ TABLE lt_pruef1 INTO ls_pruef1 INDEX 1.
Vorteile dieses Verfahrens: Das Coding ist kürzer und es muss nicht angepasst werden, wenn ein neues Schlüsselfeld dazu kommt.

- IMG-Struktur anzeigen - 11. März 2024
- ALV-Grid und Dropdown - 8. März 2024
- Finden ─ nicht suchen - 28. Februar 2024
